之前写过一篇 LLM-Wiki 模式致敬 Karpathy 那篇——讲为什么 RAG 不够、为什么 wiki-as-codebase 是更好的形态。那是抽象层。
这篇是落地层——我每天怎么用、各 source 怎么 ingest、5 个核心操作分别在解决什么、跟 v1 的关键差异、用了半个月体感如何。
如果你想”抄一份”自己用,从这篇开始。
一、v1 是什么 / 它哪里不够
v1(CC + Obsidian + 飞书 工作流 v1,2026 年 4 月以前)是一个三层文件夹模型:
Sources/ 不可变源(网页/会议/对话/邮箱)
Resources/ 派生层(Solutions/ Patterns/ Toolbox/ Learning/ 四类抽屉)
Inbox/ 待整理
这套清晰,但跑了几个月之后我看到 4 个根问题:
Resources/{Solutions, Patterns, Toolbox, Learning}是文件夹不是 wiki — 写完就死。每条笔记是孤岛,没交叉引用、没汇聚到”项目页 / 工具页 / 决策页”。3 个月后翻已经记不住哪些事互相相关/note/share是”对话→单文件”,不是”对话→知识图谱” — 一次对话沉淀一篇 markdown,但这篇 markdown 不会跟其他对话产生的 markdown 自动链接。第 N 次记下”OAuth 这个坑”时,前面 N-1 次的笔记我自己都找不到- 飞书任务 / 禅道 bug / GitLab MR 是三条平行流,没”项目页”汇聚 — 同一个项目同时有飞书 PRD、禅道 bug 列表、GitLab 的 monorepo。Obsidian 里没有一个页面把这三条流跟”我对这个项目的理解”绑在一起
- 飞书→Obsidian 单向规则自洽但不够用 — bug/MR/PRD 进个人 vault 之后无法滚雪球。它们不会跟我的”决策记录""模式""教训”产生新的链接
简而言之:v1 是个整齐的文件柜,但复利没产生。装东西越多越像仓库,不像一个会变厚的大脑。
二、v2:从文件夹到 LLM-maintained Wiki
v2 的关键转变是借了 Karpathy 提的 LLM-Wiki 模式:LLM 持续 curate 一个互联的 markdown wiki,把 wiki 当 codebase,LLM 当 programmer,Obsidian 当 IDE。
整套架构长这样:
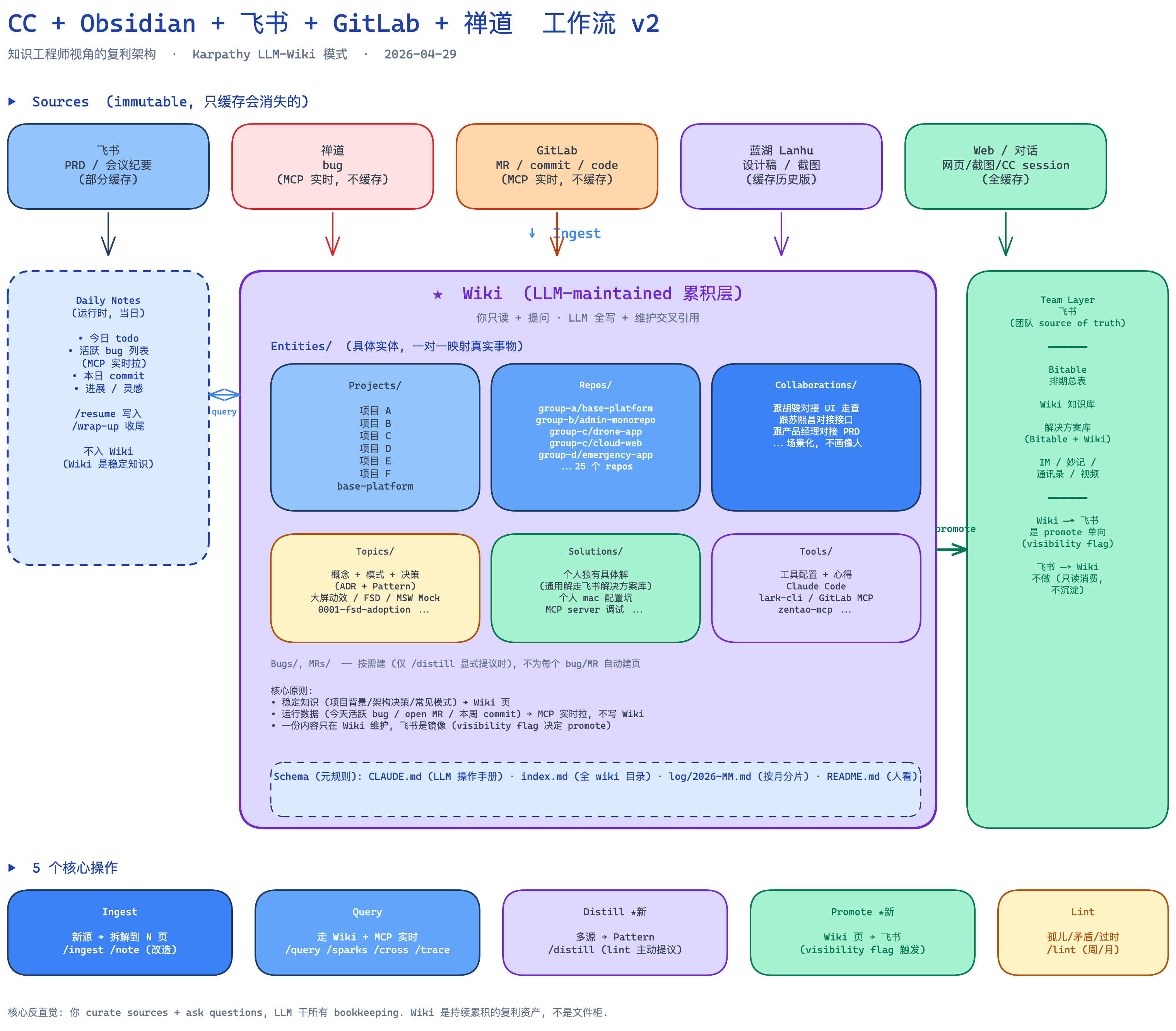
4 层结构 + 5 个核心操作。每一项都对应 v1 的一个不足。
三、4 层结构
1. Sources(不可变源缓存)
5 类外部源,按”是否会消失”决定要不要缓存到 vault:
| Source | 内容 | 缓存策略 |
|---|---|---|
| 飞书 PRD / 会议纪要 | 设计稿/决策讨论 | 缓存(飞书会改/会失联) |
| 禅道 bug | 测试请求单 | 不缓存(走 MCP 实时) |
| GitLab MR / commit / code | 代码审查/历史 | 不缓存(走 MCP 实时) |
| 蓝湖 Lanhu 设计稿 | UI 视觉 | 缓存历史版(蓝湖会改) |
| Web / 对话 / CC session | 网页/邮箱/Claude 对话 | 缓存(会失联) |
判断准则:会消失的、会被改的 → 缓存;系统里 source of truth 永远在的 → 走 MCP 实时拉,不快照到 vault。
2. Wiki(LLM-maintained 累积层)
这一层 LLM 全权写,我只 review。结构按”实体 vs 概念”分:
Wiki/
├── Entities/ ← 真实存在的东西(一对一映射事实)
│ ├── Projects/ 项目页(每项目一个)
│ ├── Repos/ 仓库页
│ └── Collaborations/合作经验(不画像人,只记场景)
├── Topics/ ← 概念 / 模式 / 决策(ADR 风格)
│ ├── Patterns/
│ ├── Reflection/
│ └── 0001-XXX.md 决策记录
├── Solutions/ 个人独有的具体解
├── Tools/ 工具配置/心得
├── Bugs/, MRs/ 按需归档(不为每个自动建页)
└── Posts/ 叙事产出(草稿 → 发布)
每个 Wiki 页 frontmatter 有:
type: project | repo | topic | solution | tool | post
visibility: private | team | public # 控制能不能 promote
related: [[X]] [[Y]] # 显式交叉引用
git_refs: [...] # 关联代码 path3. Daily Notes(运行时层,不入 Wiki)
Daily Notes/
├── 2026-05-03.md
├── 2026-05-02.md
└── ...
每天一个文件,记当日 todo / 活跃 bug / commit / 灵感。永远不归档进 Wiki。
为什么严格分开:执行场景(日常 bug / commit / 决策)和稳定知识(pattern / topic)是两类东西。前者频次高、噪音多、95% 不值得 wiki 化;后者要求结构稳定、可被反复检索。混在一起两边都累。
4. Schema(CLAUDE.md,给 LLM 看的操作手册)
Wiki/CLAUDE.md 是一份 ~360 行的 LLM 指令文档,明确:
- 每种 page type 的 frontmatter / 章节模板
- 每个操作(ingest / query / distill / promote / lint)的具体步骤
- 不可变红线(见后文)
- Schema 演进协议(LLM 觉得 schema 不合理时怎么提议改)
这是 v2 跟 v1 最本质的差异:v1 的”约定”在我脑子里,靠手维持;v2 的约定在 CLAUDE.md,LLM 自己执行 + 自己提议演进。
四、5 个核心操作
ingest / query / lint + distill (新) + promote (新)
Ingest:source → 多个 Wiki 页
/ingest <type> <id> # 显式 ingest 某条 source
/note # 把当前对话片段当 source ingest
我说”今天看到一篇关于 React Server Components 的文章 + 链接”,LLM 就:
- 读 source
- 跟我对话确认 3-5 条 takeaway
- 列出影响哪些 Wiki 页(一般 5-15 页)
- 批量 edit 这些页(更新现有页 + 创建新页)
- 写一行 log entry
- 更新 index.md
禁止:一次 ingest 只触发 1 页更新。那不叫 ingest,叫”读了一下”。
Query:走 Wiki + MCP 实时回答
/query <问题>
/sparks # alias: 最近 ingest 的灵感
/cross # alias: 跨页关联
/trace # alias: topic 演进
LLM 先读 index.md 找候选页,drill into 2-5 页,需要实时数据时(今天活跃 bug / open MR)走 MCP 拉,不读 Wiki。回答时引用 [[页名]]。
如果回答本身有累积价值(“这答案不错”),LLM 主动提议 file back—— 把这次 query 的产出写回某个现有 Topic 页,下次自动可被检索到。
Distill:多个 ingest → 蒸馏成 Topic / Pattern
/distill # 主动蒸馏
Karpathy 原版没有这条——他的研究场景频次低,每篇论文一页 wiki 就够。但执行场景下我每周重复同类工作 10+ 次(“又一个权限 bug”、“又一次大屏对接”),不蒸馏 wiki 就是另一种”文件柜”。
Distill 干的事:找 ≥3 条相似 ingest → 抽出共性 → 提议建/更新 Topics/<pattern>.md → 把原始 ingest log 加 backlink 到这页。
这条最值钱。前 2 个月跑 v2 时蒸馏出来的 Topic 数比 ingest 总数低 1 个数量级,但这些 Topic 是真正会被反复 query 命中的。
Promote:Wiki → 飞书(visibility flag 触发)
/promote # 把所有 visibility ≠ private 的页推到飞书
/promote <slug> # 显式推某一页
Wiki 页 frontmatter 有 visibility:
private(默认):仅个人 vaultteam:飞书部门知识库public:飞书解决方案库(全公司可见)
/promote 把符合的页推过去,回写 feishu_url + promoted_at 到 wiki frontmatter。
单源原则:内容只在 Wiki 维护,飞书是镜像。Lint 时检查 wiki ↔ 飞书 是否漂移。
Lint:周/月健康检查
/lint # 跑全套
/lint <page-glob> # 局部
6 类检查:
- 孤儿页(没 backlink/inlink/不在 index)
- 矛盾(Page A 说 X,Page B 说 not X)
- 过时(引用已 closed 的 bug / 已删 repo / 已变更的 commit)
- 缺失(反复提到的实体但 Entities 里没建页)
- shared 漂移(visibility ≠ private 的页跟飞书镜像不一致)
- 蒸馏候选(≥3 条相关 ingest 但还没合 Topic)
前置:lint 之前自动 cd Wiki && git commit -am 'pre-lint snapshot',写坏可一键 revert。
五、跟 v1 的 5 点关键差异
| # | v1 | v2 | 为什么改 |
|---|---|---|---|
| 1 | 3 层(Sources / Resources / Inbox) | 4 层(+ Daily Notes 显式拆出来) | Karpathy 原版 implicit,我们 explicit。运行数据 ≠ 稳定知识 |
| 2 | 3 操作(note / share / lint) | 5 操作(+ distill + promote) | 执行场景重复频次高必须 distill;个人↔团队的桥必须 promote |
| 3 | 一个 bug / MR → 一页 wiki(手动) | 按需建 | 95% bug 是 UI 微调,wiki 化就是文件柜。只有 /distill bug <id> 显式提议时才建 |
| 4 | 稳定知识 + 运行数据混在 Resources/ | 严格分(Wiki 稳定,MCP 运行时) | “今天活跃 bug 列表”永远不写进 wiki 当快照——快照立刻过期 |
| 5 | 飞书是 source 也是 sink | 飞书只是 sink,wiki 是 source | 单源原则。Lint 检查 wiki ↔ 飞书 漂移 |
第 3 条是最反直觉但救命的:v1 时我傻乎乎给每个有点意思的 bug 建一页,3 个月后 Bugs/ 文件夹有 200+ 文件,95% 永远不会再被翻。v2 改成”默认走 MCP 实时拉,只有蒸馏出来的模式才建 wiki 页”,文件数从 200+ 降到 5-10,但这 5-10 页都是真有用的。
六、Schema 不可变红线
Wiki/CLAUDE.md 里的硬约束:
- ❌ 把禅道 bug / GitLab MR 列表当快照写进 wiki 页(永远走 MCP 实时)
- ❌ 替用户手工写 wiki 内容(LLM 写,用户 accept)
- ❌ 修改 CLAUDE.md schema 不打招呼(要走”提议→accept→edit”流程)
- ❌ 跨过 visibility flag 直接 promote(单源:wiki,飞书是镜像)
- ❌ 把”今天 commit log""本周 PR”等运行时数据写进实体页
- ❌ 在 Collaboration 页评价人(只记场景,不画像)
最后一条容易忽略但很重要——Entities/Collaborations/ 我用来记”跟某个角色在某个场景下的合作经验”,不是给人画像。“在 UI 走查这个场景下,他通常关注 X 不关注 Y”是合作经验;“他做事不细心”是画像。前者帮我下次干得更好,后者会把同事关系搞坏。
七、半个月用下来的体感
跑了 ~2 周。几个变化:
1. 同样的 bug 类型不再”重复想” — 以前每次踩”权限 bug 跨服务”我都重新查一遍。现在 Topics/Patterns/auth-cross-service.md 一开始 distill 的时候 LLM 把过往 5 个相关 bug 总结进去了,下次 /query 直接命中。
2. 项目页变成真有用 — Entities/Projects/<X>.md 不再是冷清的元信息列表。LLM 会在每次 ingest 涉及这个项目时主动更新”当前活跃模式""关键决策记录""历史里程碑”等节,3 周后翻看是一份真实有温度的项目史。
3. 飞书那边的”个人方案库”开始填内容 — /promote 跑完 visibility:public 的 Topic 自动推到飞书解决方案库,不再需要我手动复制粘贴。
还卡的地方:
- Distill 触发频率太低 — 我得手动跑
/distill。理想是 LLM 在 ingest log 累积到一定量时主动提议蒸馏,目前还没自动化 - Bug/MR 集成的 Phase 3 还在跑 —
/bug start <id>自动从禅道拉 bug + 找对应 repo + 切分支这个链路还在调试 - Schema 演进 — CLAUDE.md 的几条规则我不时会改,但还没建立”schema diff review”流程。改的时候容易破坏既有约定
八、要不要抄
不建议直接抄。这套是给”个人维护 + LLM 增强”的,不是团队系统。核心思路可以抄:
- LLM-maintained 不是 LLM-generated — 一次性生成笔记 ≠ 持续 curate 知识图谱
- 稳定知识跟运行数据严格分 — 这条决定 vault 不会变成日志文件
- 单源原则 — 不论几条目的地,编辑只在一处
- Schema 显式 + 可演进 — CLAUDE.md 是 vault 的”宪法”,写下来 + 跟 LLM 共同迭代
- lint 前必 git commit — 让 LLM 自由 write 的前提是你随时能 revert
具体的 4 层 / 5 操作 / /ingest /promote 这些 skill 命名是我个人的。你完全可以做不同切分——只要核心思路在,工具栈不重要。
关联:
- LLM-Wiki 模式:当 AI 持续 curate 你的知识库 — Karpathy 模式抽象 + 我的扩展
- AI 作为第二大脑:从一段油管视频到我的工程落地 — Maxwell Wilson 视频对比
- Karpathy 原版 gist — 起点