个人知识库这件事,我换过三套方案:直接 dump 到 Obsidian、靠 RAG 召回、最后落到 LLM-Wiki 模式。前两者总在某个规模后翻车——RAG 检索从零算上下文相似度,每次都重做一遍 bookkeeping。Karpathy 那篇 gist 说穿了一个事:让 LLM 持续累积维护一个互联的 markdown wiki,bookkeeping 摊到每次 ingest。
RAG 的根本不爽
RAG 的工作流是:你有一堆原始文档(PDF / 网页 / 录音转文字),每次查询时模型把 query embedding 出来,跟文档块做相似度,召回 Top-K,喂给 LLM 生成答案。
问题在于:
- 没有累积。每次查询从零检索,模型不”记得”上次推导的中间结论
- 没有结构。文档块是切片,相邻块可能讲不同事,模型靠相似度”猜”语义边界
- 维护永远不发生。原始文档错了、过时了,没人改;交叉引用、矛盾标注、术语统一都是手工活
- 看不见全貌。你不知道知识库里到底有什么,哪些是 hub,哪些是孤岛
人类 wiki 死掉是同样的原因——不是阅读和思考累,而是 bookkeeping 累:每次更新一处要联动同步好几页交叉引用、确认没产生矛盾、维护索引。维护成本增长比价值快,wiki 就腐烂了。
Karpathy 的反直觉
You never (or rarely) write the wiki yourself — the LLM writes and maintains all of it.
LLM-Wiki 的核心是把这个 maintenance burden 完全甩给 LLM:
| 层 | 角色 | 谁写 |
|---|---|---|
| Raw Sources | 不可变源(网页 / 论文 / 会议纪要) | 你手动添加 |
| The Wiki | LLM-generated markdown 集合(摘要 / 实体页 / 概念页 / 比较) | LLM 全权 |
| The Schema | CLAUDE.md,告诉 LLM wiki 怎么组织 | 你跟 LLM 共同演进 |
三个核心操作:
| 操作 | 触发 | 干啥 |
|---|---|---|
| Ingest | 加新源 | 读源 → 写摘要页 → 更新 index → 更新 N 个相关页 → 写 log |
| Query | 你问问题 | 走 wiki + 引用回答,答案可以 file back 成新页(compounding!) |
| Lint | 周/月跑 | 找矛盾 / 孤儿 / 过时 / 缺口,让 wiki 不腐烂 |
你只 curate sources(决定什么进 inbox)+ exploration(决定下一步往哪挖)+ accept proposals(LLM 提议改什么,你点头)。LLM 干所有 bookkeeping,因为:
- LLM 不会无聊——更新 15 个文件不会嫌烦
- LLM 不会忘——交叉引用同步是它的标准操作
- maintenance cost 趋近于 0 → wiki 能持续保鲜
Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase.
我的落地版:4 层 5 操作
跑了一段 Karpathy 原版后,我加了两层:
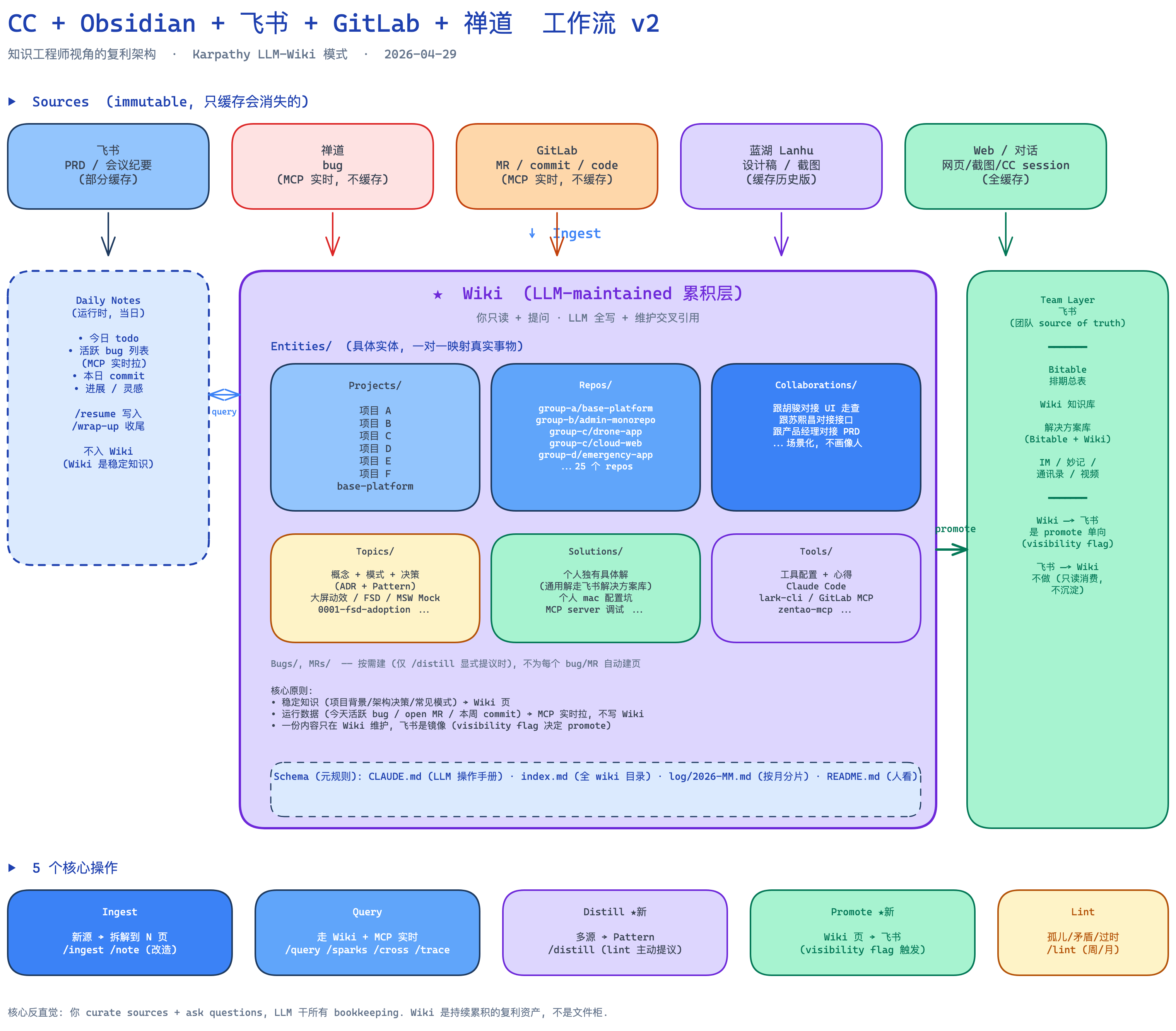
Sources (immutable) ─┬─ ingest ─→ Wiki (LLM-maintained) ─┬─ promote ─→ Team (飞书)
│ ├─ query ─→ 你的问答
│ └─ distill ─→ 新的 Wiki 页
│
└──────── Daily Notes (运行时, 不入 Wiki)
| 层 | 跟 Karpathy 原版的差异 |
|---|---|
| Sources | 一致:不可变缓存 |
| Daily Notes | 新增 · 当日 todo / bug / commit / 灵感的运行时层,不归档进 Wiki |
| Wiki | 一致:LLM-maintained 累积层 |
| Schema | 一致:Wiki/CLAUDE.md |
操作多了 2 个:
| 操作 | 干啥 |
|---|---|
| Ingest | 拆解 source 到多个 Wiki 页 |
| Query | 走 Wiki + MCP 实时数据回答 |
| Distill | 多个相似 ingest 蒸馏成 Topic / Pattern / Decision |
| Promote | Wiki 页 → 飞书团队知识库(有 visibility: team|public 标记的) |
| Lint | 健康检查(孤儿 / 矛盾 / 过时 / distill 候选) |
把 Daily Notes 跟 Wiki 严格分开是因为:执行场景(日常 bug / commit / 决策)和稳定知识(pattern / topic)是两类东西。前者频次高、噪音多、95% 不值得 wiki 化;后者要求结构稳定、可被反复检索。混在一起两边都累。
Distill 和 Promote 是为了把”个人 → 团队”通路打开:个人 wiki 是私有,但里面有些 pattern 同事应该看到。visibility: team \| public 标志触发 promote 推到飞书,私有的留 vault。
一个反直觉细节:让 LLM 写,你只 review
我刚开始用的时候总忍不住”自己整理”——读完一篇论文,习惯性手动开 Obsidian 写笔记。Karpathy 这一段说得很重:
Vault 里只能存我的思考,不能存 AI 的看法,否则模式分析时会混淆谁的想法。但 wiki 是 AI 写的——因为它是综合多源的累积层,不是你的私人思考。
在我现在的设计里:
- Daily Notes 我自己写——当天的灵感、决策、感受,纯粹我的
- Wiki LLM 写——基于 Sources 综合而成的稳定知识,引用得清晰
两者不能互相污染。Daily Notes 不会被 ingest(它本身就是源,后面会被 distill 进 Wiki)。Wiki 不会被我手改(除非 schema 变更或纠错)。
这套有什么实质收益
跑了几周后最明显的差异:
- 新源进来时已经被组织好——加一篇论文进 Sources,跑
/ingest之后,相关 Topic 页会自动更新,相关 Pattern 会被识别,矛盾会被标出 - 问问题不用想去哪查——Wiki 自己有 index.md,LLM 先扫 index 收紧,再 drill into 具体页。中等规模(~100 源、数百页)根本不需要向量检索
- 思考有 compounding——
/query的答案可以 file back 成新 wiki 页,下次问相关问题时就站在上一次的肩膀上 - 看得见知识形状——Obsidian graph view 直接告诉你哪些是 hub,哪些是孤岛
Memex(1945)那个梦想:私有的、主动 curate 的、document 之间的关联跟 document 本身一样重要的知识库。Bush 当年没解决的是 “谁来维护”。LLM 解决了。
如果你也在 Obsidian 里堆了几百篇笔记但不知道怎么用,把 RAG 那套换成 LLM-Wiki 试试。维护从负担变成自动,剩下的事是你想问什么。