我推动的一次大规模前端架构重构最后落到一句话上:让”从一个大单仓抽离一个业务域成独立产品”,从手术变成一条命令。
起点是一个堆了 28 个业务域的大前端单仓——设备、劳务、考勤、安全、薪酬、大屏、视频监控……每个都有独立成 SaaS 的可能,但代码层面强耦合:目录结构按功能切而不是按领域切,共享代码埋在业务里,基础设施和业务代码长在一起。
想把”设备管理”单独抽出来做成独立产品,意味着手工剥离几百个文件、修几十处隐式依赖、重建一套 CI/CD,代价高到没人愿意动。
这次重构要做的事——在一次架构动作里把这层耦合彻底拆掉。这篇是整套方案的落地笔记。
一、问题不是”代码不整洁”,是产品化
驱动力不是代码整洁,是产品化——每个业务域都要具备独立交付、独立部署的能力,而不是 N 个域捆在一个壳子里一起出。
这个目标决定了整套架构。基建层、FSD 方法论、应用级 monorepo、CI/CD、原子部署、Turbo Cache、缓存清理 —— 这些工作全部为这一个目标服务,彼此不是并列关系,而是解锁关系。
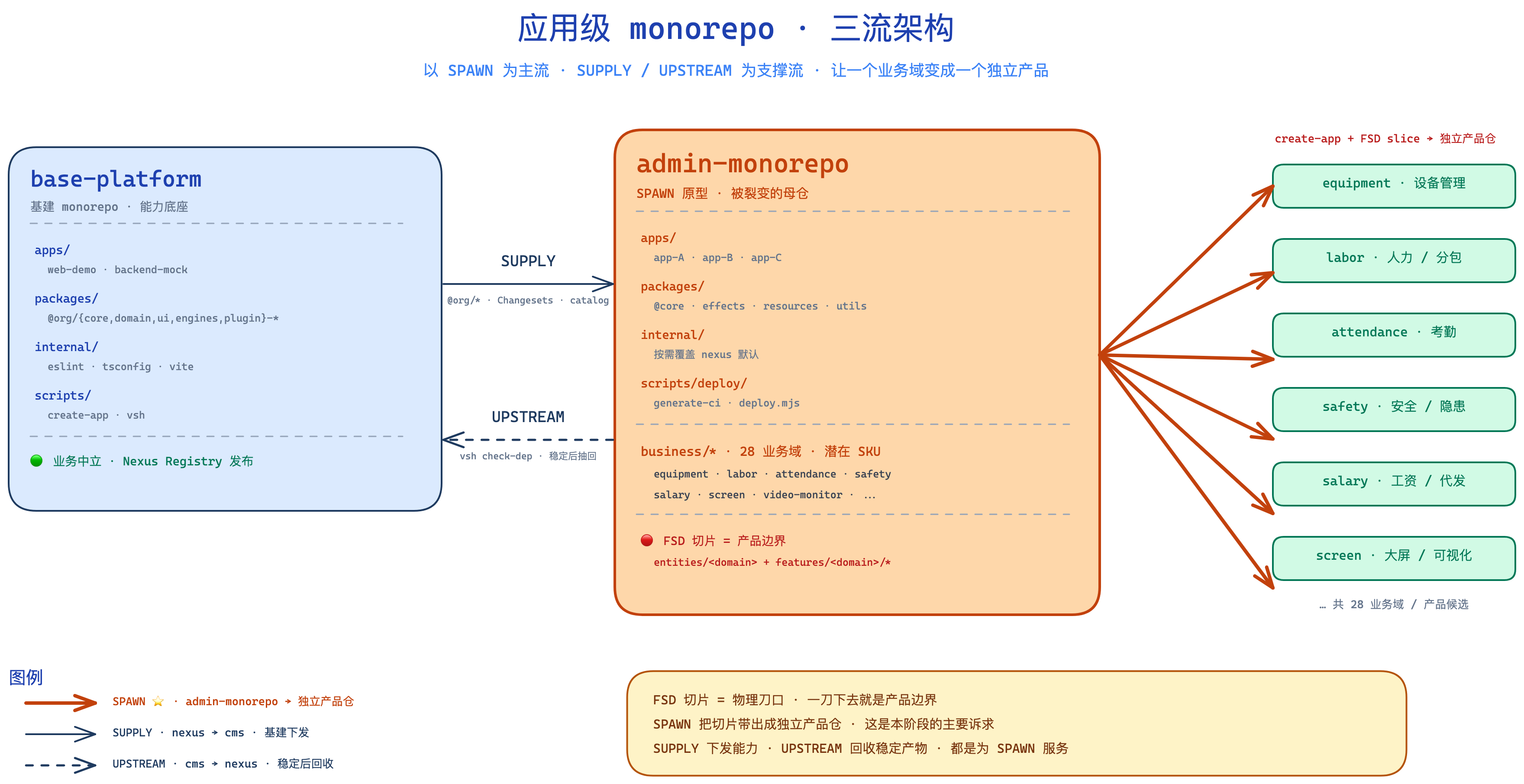
二、三流模型:SUPPLY / UPSTREAM / SPAWN
做到这一点需要一个三流架构,不是两层塔也不是双向供给那么简单。三条流缺一不可:
| 流名 | 方向 | 承载 | 作用 |
|---|---|---|---|
| SUPPLY | 基建库 → app | Changesets 发版 + pnpm catalog | 所有产品消费同一份 @org/*,升级一处全仓受益 |
| UPSTREAM | app → 基建库 | 应用仓 packages/ 沉淀稳定后抽回基建库 | 让基建层始终贴合真实产品需求,避免纸上谈兵 |
| SPAWN ⭐ | 一个 app → 多个 product app | FSD 切片 + 脚手架模板 + 可复用 CI/CD 模板 | 把母仓里的业务域按需抽离成独立产品仓,这是整个架构的终极目的 |
SUPPLY 和 UPSTREAM 是支撑流,服务于 SPAWN 这条主流。没有前两条,SPAWN 的时候就得手工拷贝基础代码;没有 SPAWN,前两条只是”代码组织得比较整齐”的自我感动。
不是”三层静态塔”,而是以 SPAWN 为主流、SUPPLY/UPSTREAM 为支撑流的动态架构。两个互为镜像的 monorepo(基建库和应用仓)通过 FSD 方法论组织业务,最终要让应用仓能按业务域裂变出一整批独立产品仓。
三、镜像结构:两仓四维对照
两仓结构一一对应,但每个维度在三流里的角色不同:
| 维度 | 基建库 (base-platform) | 应用仓 (admin-monorepo, SPAWN 原型) | 在三流里的角色 |
|---|---|---|---|
apps/ | web-demo / backend-mock · 自测 playground | 真业务 app(业务 A / B / C) | SPAWN 的切分对象 —— 未来每个 app + 若干业务域切片会被整体搬到新产品仓的 apps/ |
packages/ | @org/* · 业务中立、对所有产品开放 | @core / effects / resources / utils · 本仓私有薄封装 | SUPPLY(被消费)+ UPSTREAM(应用层稳定抽象被提升回基建库);SPAWN 时这层是取舍点 |
internal/ | eslint / tsconfig / vite / tailwind / node-utils(发布到 Registry) | 项目私有配置(按需启用,可本地覆盖) | SUPPLY —— 新产品仓直接继承基建库发布的 @org/*-config,只做最小化覆盖 |
scripts/ | 脚手架 · 内部 CLI · 发版脚手架 | generate-ci · deploy.mjs · diagnose-server | SPAWN 的两个抓手:基建库侧脚手架负责起新仓,应用仓侧 deploy/ 未来要抽成 @org/ci-kit + @org/deploy-kit 供每个产品复用 |
四条核心判断:
- 结构同构 — 两个 monorepo 长得一模一样,肌肉记忆能迁移;裂变出来的新产品仓也继承同一套结构,天然可读可维护
- 能力异步 — 基建库节奏慢(语义化版本),应用仓节奏快(每日迭代),中间用 pnpm catalog 做版本解耦
- 边界可渗透 — 应用仓里写私有实现,证明普适后抽回基建库。UPSTREAM 让基建层始终贴合真实需求
- FSD 是三流共用的业务方法论,也是 SPAWN 的物理刀口 — 两仓的
apps/*/src/都走 app/pages/widgets/features/entities/shared 六层。切片是产品边界:未来拆产品时,刀口落在entities/<domain>+features/<domain>/*+ 相关widgets/pages,沿着物理目录就切出去
四、基建层:五组分层 + 依赖方向硬约束
4.1 五组分层
基建库的 packages/ 没有把所有包平铺在同一层,而是按职责切成五组,形成从底到顶的单向依赖链:
core/ → domain/ → ui/ → engines/ → plugins/
底层工具 领域中立能力 UI 框架 领域引擎 三方壳子
core/— HTTP 客户端、GraphQL 客户端、缓存、共享类型domain/— 权限、i18n、偏好、通用 store、领域工具ui/— 组件、composables、layouts、primitives、widgets(含 admin 壳)engines/— form 引擎、document 引擎、GIS 引擎、metadata 引擎、workflow 引擎plugins/— echarts、motion、表格库等三方壳子
分组的三个理由:
- 依赖方向可视化 — 目录层级即依赖方向。翻目录就能判断一个包处于哪一层、能依赖谁
- 和下游 FSD 六层的对应关系 —
core/*和domain/*通常落到 FSD 的shared/;ui/*落到shared/ui/或widgets/;engines/*落到entities/或features/ - SUPPLY 流的按需消费 — 未来轻量产品仓可能只需要
core/+domain/+ui/就够了,不需要拉engines/gis或plugins/echarts。分组让”挑着用”的边界天然清晰
4.2 依赖方向不靠约定,靠 ESLint 强制
五组之间的单向依赖不是靠约定,而是靠 @org/eslint-config 里的 no-restricted-imports 规则硬性阻断:
| 包所在层 | 禁止引入 | 原因 |
|---|---|---|
core/* | @org/domain-*, @org/ui-*, @org/engines-*, @org/plugin-* | 底层工具不能依赖上层能力 |
domain/* | @org/ui-*, @org/engines-*, @org/plugin-* | 领域逻辑不能依赖 UI |
ui/* | @org/engines-*, @org/plugin-* | UI 框架不能依赖引擎和插件 |
违反方向的 import 在 pnpm lint 阶段直接报错,CI 里无法通过。配合循环依赖检测,两道防线确保分层不被破坏。
4.3 组件适配器模式
ui/ 包采用组件适配器模式 — 核心 UI 组件不直接引用任何特定 UI 框架,而是通过一个全局注册表在运行时解析具体实现:
应用启动时调用 initComponentAdapter()
↓
注册组件映射: 'Input' → AntInput / ElInput / NInput
注册事件映射: value vs modelValue, update:value vs update:modelValue
↓
@org/ui-* 核心组件按名称动态解析,不含任何框架 import
这个模式的意义:
- SPAWN 产品的 UI 自由度 — 不同产品仓可以选不同的 UI 框架(Ant Design Vue / Element Plus / Naive UI),只要注册对应的适配器,
@org/ui-*不用改一行代码 - 基建层的框架中立性 —
@org/engines-form是 schema 驱动的表单引擎,底层用@org/ui-primitives(基于无头组件库)渲染,不绑定具体 UI 库 - 渐进迁移 — 框架升级时改适配器层就行,不用动业务代码
4.4 发布链路:Changesets → 内网 Registry
基建库通过 Changesets 管理发版:
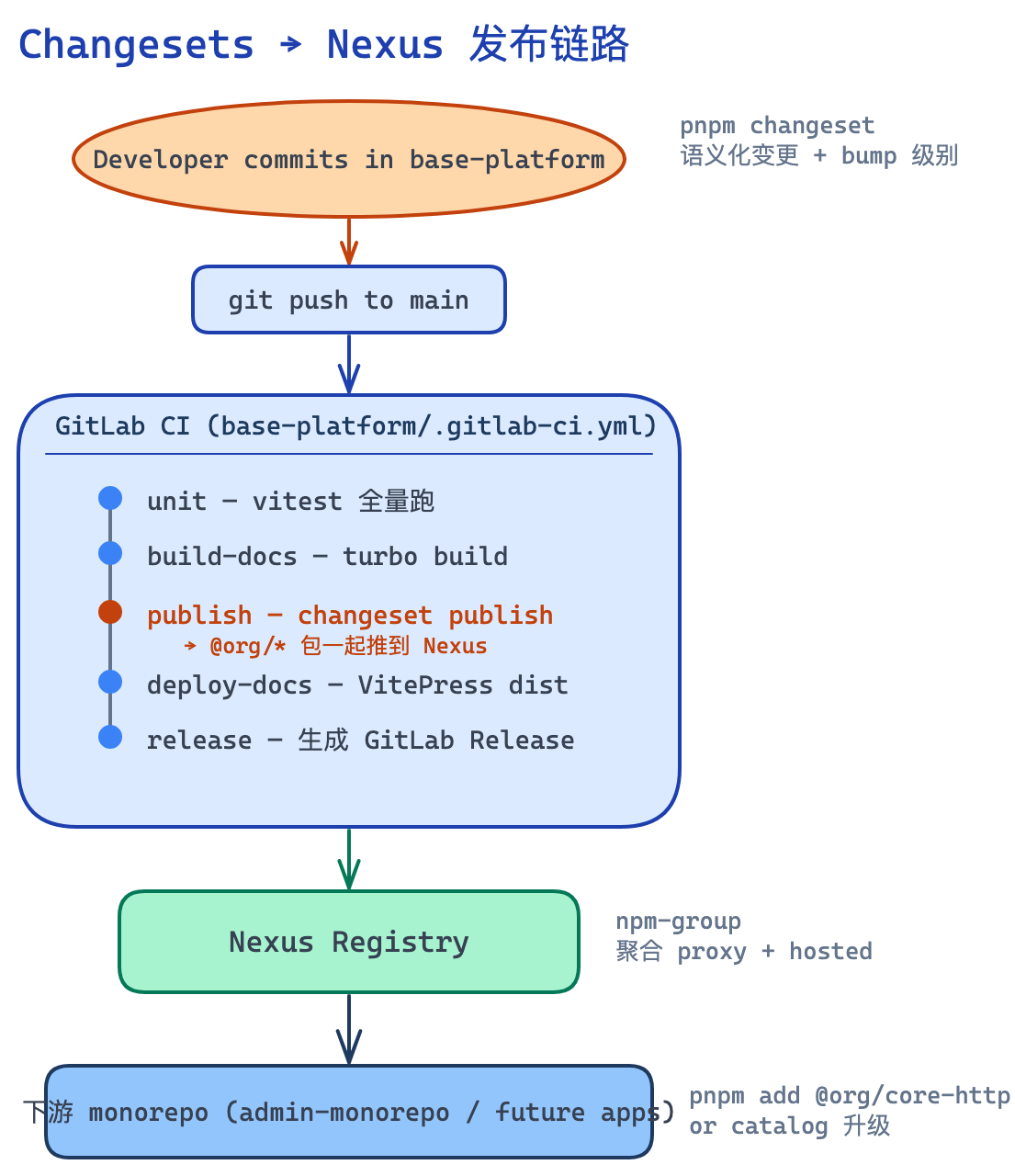
开发者 changeset 描述变更
↓
PR 合入 main
↓
CI 自动:
1. 整理 changeset 文件
2. 计算每个包的版本 bump (patch/minor/major)
3. 生成 CHANGELOG
4. pnpm publish 到内网 Registry
↓
下游应用仓通过 pnpm catalog 升级版本
应用 monorepo 通过 pnpm catalog 统一锁版本,避免每个 workspace 包重复声明:
# 应用仓库的 pnpm-workspace.yaml
catalog:
'@org/core-http': ^1.0.5
'@org/domain-access': ^1.0.5
'@org/ui-layouts': ^1.0.5// 应用仓库的某个 workspace 包
{
"dependencies": {
"@org/core-http": "catalog:",
"@org/ui-layouts": "catalog:"
}
}升级基建库时只改一处 catalog: 条目,全仓受益。
五、业务层:FSD 六层 + 切片即产品边界
5.1 为什么选 FSD
Feature-Sliced Design 是一套前端目录分层 + 依赖方向约束的规范,不绑框架不绑库。
选它就一个理由:它的切片天然就是拆产品时的物理刀口,沿 entities/<domain> + features/<domain>/* 目录切就行。依赖方向清晰、跨域隔离那些都是附赠品。
5.2 六层切片
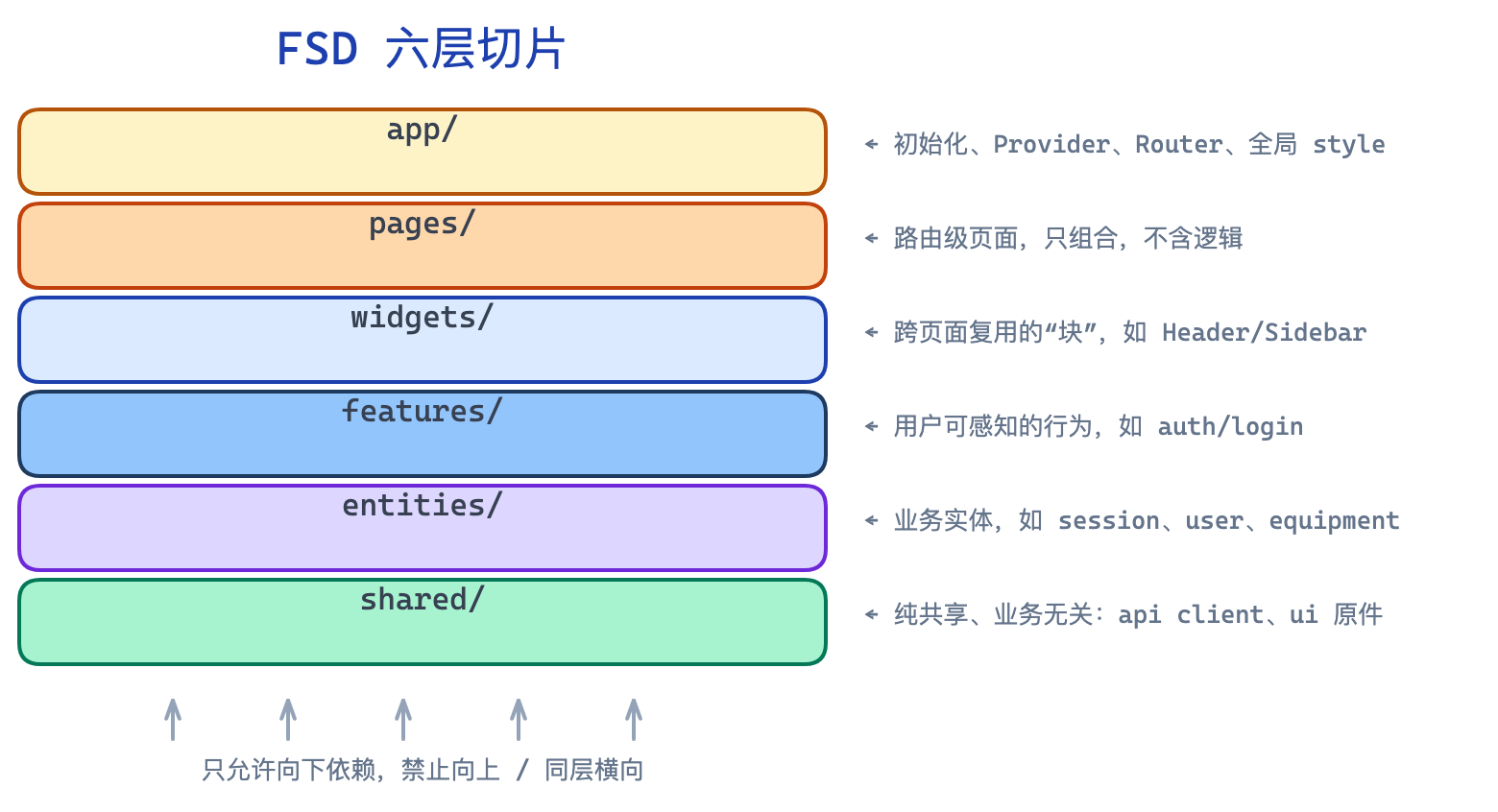
app/ ← 应用启动、全局 Provider、路由装配
pages/ ← 路由级页面 (组合 widgets + features)
widgets/ ← 跨页复用的 UI 块
features/ ← 用户可感知的交互 (按钮、表单、对话框)
entities/ ← 业务实体的模型、store、api、schema
shared/ ← 业务无关的共享基础件
核心约束:
- 单向依赖 —
app可以引pages,pages可以引widgets……shared不能引任何层 - 同层隔离 —
features/auth-login不能直接引features/table-export,需要提升到 widgets 或 page 级编排。这条规则对 SPAWN 至关重要 —— 同层隔离意味着切片之间没有隐式耦合,拆产品时不会漏拎文件 - 切片化 — 每层内部按业务切片组织:
entities/equipment/,entities/labor/,features/equipment/add/,features/equipment/assign/。这是 SPAWN 的物理刀口:拆设备产品时,所有*equipment*的目录整体搬走就完事
5.3 每层职责速查
| 层 | 例子 | 职责 | 反例 |
|---|---|---|---|
app/ | main.ts, providers/, router/, bootstrap.ts | 应用启动、全局 Provider、路由装配 | 写一个 user-list.vue |
pages/ | pages/equipment-list/, pages/labor-attendance/ | 组合 widgets/features 成完整路由页 | 直接写业务逻辑 |
widgets/ | widgets/header/, widgets/dashboard-card/ | 跨多页复用的 UI 块,含少量组合逻辑 | 放 entities 层的模型 |
features/ | features/auth/login/, features/equipment/assign/ | 用户可感知的交互(按钮、表单、对话框) | 跨业务域引用其他 feature |
entities/ | entities/session/, entities/equipment/ | 业务实体的模型、store、api、schema | 依赖 features 或 pages |
shared/ | shared/api/client.ts, shared/ui/button/ | 业务无关的共享基础件 | 出现任何业务名词 |
5.4 FSD 与基建层的配合
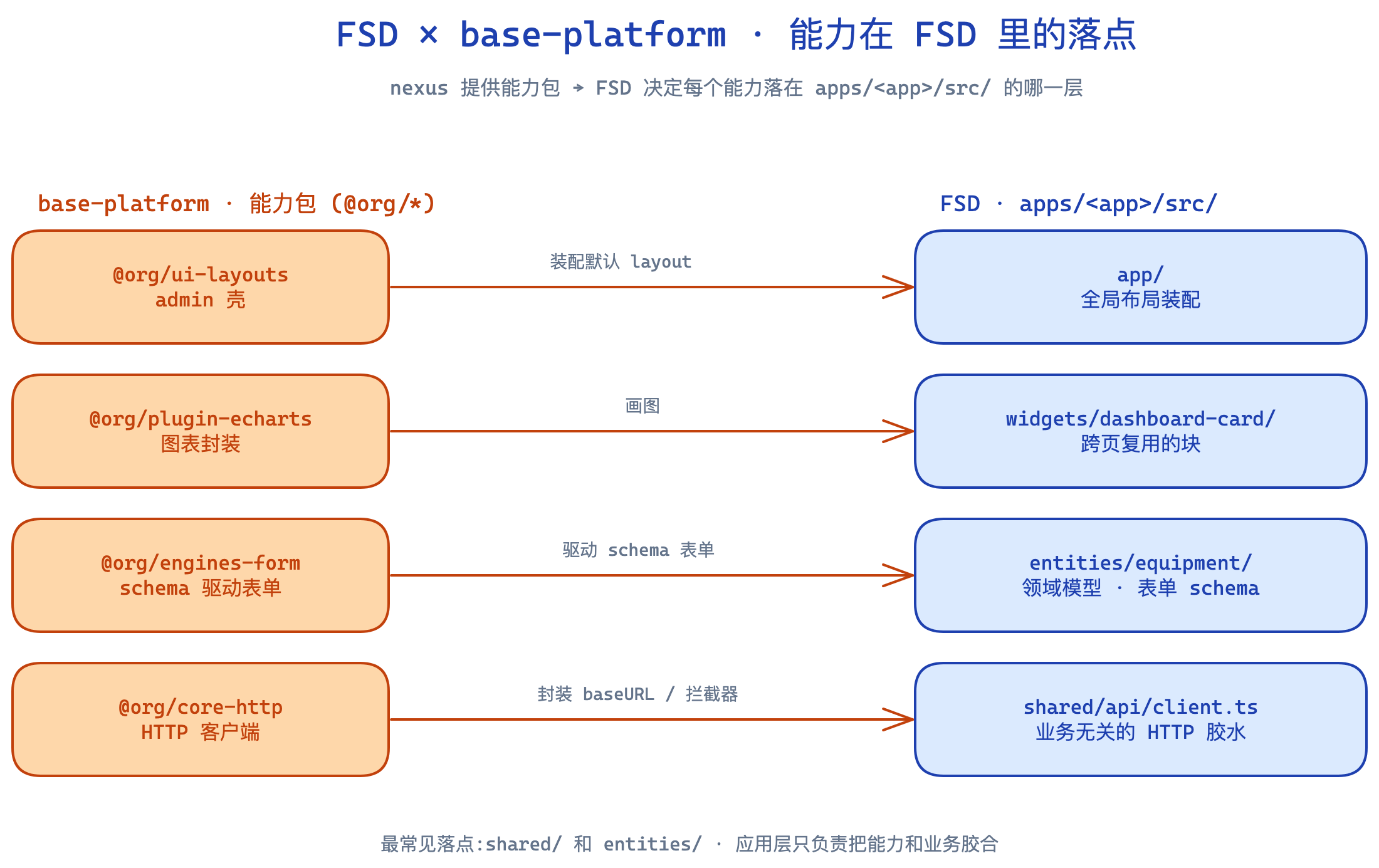
基建库提供”能力”,FSD 组织”业务”,应用把两者胶合。基建库的每一个 @org/* 包最终都会落到 FSD 的某一层(最常见是 shared/ 和 entities/),应用层只写业务代码。
不冲突,反而互补:基建库的能力包从外部以 npm 依赖形式进来,FSD 决定每个能力在 apps/*/src/ 里落在哪一层。
六、部署:原子 symlink
6.1 为什么要改掉 rsync dist/
早期做法是 rsync dist/ → /data/.../dist/,让 nginx 实时读取。问题:
- rsync 过程中 nginx 可能读到半旧半新文件,chunk 404 白屏
- 没有版本概念,回滚得靠备份目录手动覆盖
- 增量传输效率差,每次都是全量
6.2 目录布局
/data/.../app-name/
├── releases/
│ ├── 20260412-193015-a9ebf220/ ← 当前服务的版本
│ │ ├── index.html
│ │ ├── assets/
│ │ └── version.json
│ └── 20260411-160522-55305c1e/ ← 上一版,保留作 --link-dest 基准
└── dist -> releases/20260412-193015-a9ebf220 ← symlink,nginx 指向这里
Release ID 格式:YYYYMMDD-HHMMSS-<shortSha> — 字典序即时间序,方便 sort -r。
6.3 部署脚本四步法
┌─ Step 1 ─ 准备远端结构
│ mkdir -p releases/
│ if dist 是真目录 → mv dist dist.legacy-<ts>(首次迁移备份)
│
├─ Step 2 ─ 解析 --link-dest 基准
│ readlink dist → releases/<prev>
│ rsync 用 --link-dest=../<prev> 硬链未变的文件(省磁盘 + 带宽)
│
├─ Step 3 ─ rsync 到新 release
│ rsync -avz --delete \
│ --link-dest=../<prev> \
│ apps/<app>/dist/ → releases/<new-id>/
│
└─ Step 4 ─ 原子切换 + 清理
ln -sfn releases/<new-id> dist.tmp.$$
mv -Tf dist.tmp.$$ dist ← rename(2),一瞬间
for legacy in dist.legacy-*; do rm -rf "$legacy"; done
ls releases | sort -r | tail -n +$((KEEP+1)) | xargs rm -rf
6.4 为什么说它是原子的
核心在这一行 mv -Tf dist.tmp dist:
mv -T(即--no-target-directory)强制把dist.tmp当作目标完整路径,而不是把它放进dist/里- POSIX
rename(2)系统调用保证原子替换:任意时刻 nginxopen(dist/...)要么看到旧指向,要么看到新指向,绝不会看到”半个”状态 - symlink 指向真目录,相对路径解析正常,nginx 一行都不用 reload
6.5 回滚:秒级生效
ssh -p <port> <user>@<host>
cd /data/.../app-name/
ls releases/ # 确认有 prev release
ln -sfn releases/<prev-id> dist.tmp.$$
mv -Tf dist.tmp.$$ dist # 秒级切回KEEP_RELEASES = 2 保留前一版作为回滚基准,再老的就裁掉。
6.6 Chunk load 容错
前端配套写一个兜底组件:
- 监听
window 'error'(capture phase)和window 'unhandledrejection' - 识别
Failed to fetch dynamically imported module这类 chunk load 失败 - 用
sessionStorage打时间戳防死循环 - 自动
location.reload()拉新 index.html,下一次加载到新 chunk
要兜的场景 —— 用户加载了老 index.html 后 symlink 切到了新 release,旧 chunk 已经不在了。原来这种情况会白屏,现在会自动恢复。
七、Turbo Remote Cache:CI 加速的唯一手段
7.1 为什么必须上
Turbo 的缓存命中分成两级:
┌─────────────┐
│ Local Cache │ ← .turbo/ (单机,冷启动全 miss)
└──────┬──────┘
│ miss
▼
┌─────────────┐
│Remote Cache │ ← http://turbo-cache:13000
└──────┬──────┘ (跨 CI runner / 开发者机器共享)
│ miss
▼
┌─────────────┐
│ Full Build │ ← 真正跑 vite/tsc
└─────────────┘
CI 场景下每个 pipeline 用的是临时 docker 容器,没有 local cache。Remote Cache 是唯一能上的加速手段——这也是我一开始就把它列成必选项的原因。
7.2 工作链路
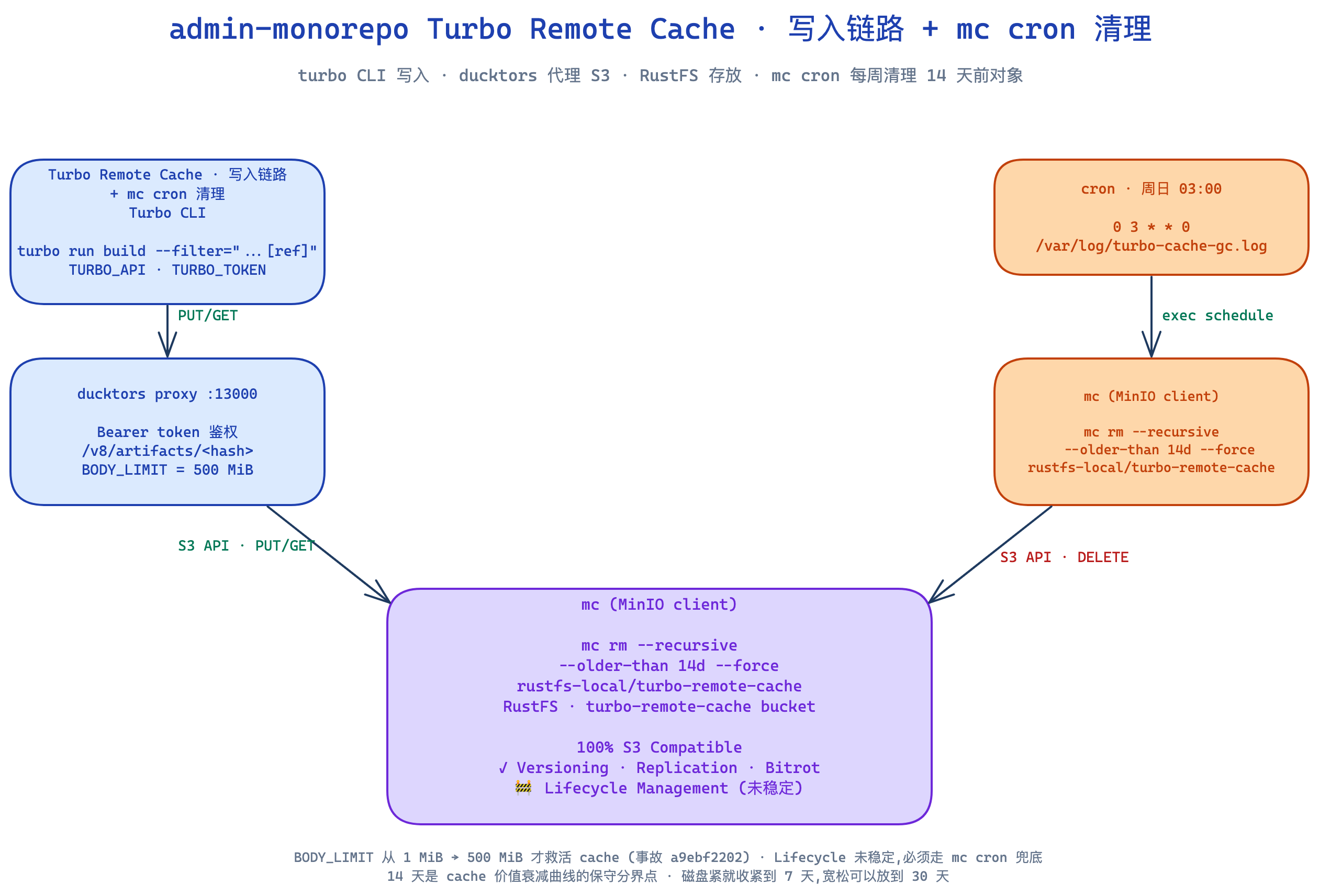
turbo CLI ──PUT/GET──▶ ducktors proxy ──S3 API──▶ S3-兼容 bucket
│ (:13000) (e.g. RustFS / MinIO)
│
└─ 读 env:
TURBO_API = http://<host>:13000
TURBO_TOKEN = <secret>
TURBO_TEAM = <team-name>
TURBO_REMOTE_CACHE_SIGNATURE_KEY = <secret>
ducktors/turborepo-remote-cache 是 Fastify-based 的 S3 转发层,做三件事:
- 鉴权(校验
Authorization: Bearer <TURBO_TOKEN>) - Turbo 协议适配(
/v8/artifacts/<hash>) - 把请求转给后端 S3
7.3 缓存清理
Remote Cache 只增不减,bucket 越大越占磁盘。链路上没有任何一环负责清理——turbo CLI 只读写、proxy 只转发、S3 后端的 lifecycle 配置可能不可用(实测某些自建 S3 的 lifecycle 还在 Under Testing 状态)。
兜底方案:用 mc(MinIO 官方 S3 客户端)+ cron 按年龄删:
# 周日凌晨 3 点清 14 天前的
0 3 * * 0 /usr/local/bin/mc rm --recursive --older-than 14d --force \
<alias>/turbo-remote-cache \
>> /var/log/turbo-cache-gc.log 2>&1阈值选 14 天 —— cache 命中价值随时间快速衰减:当天命中率很高(多人并发推同 task),一周后大部分 hash 已过期,两周后基本是死数据。14 天是保守但不浪费的分界点。
八、CI/CD 四阶段
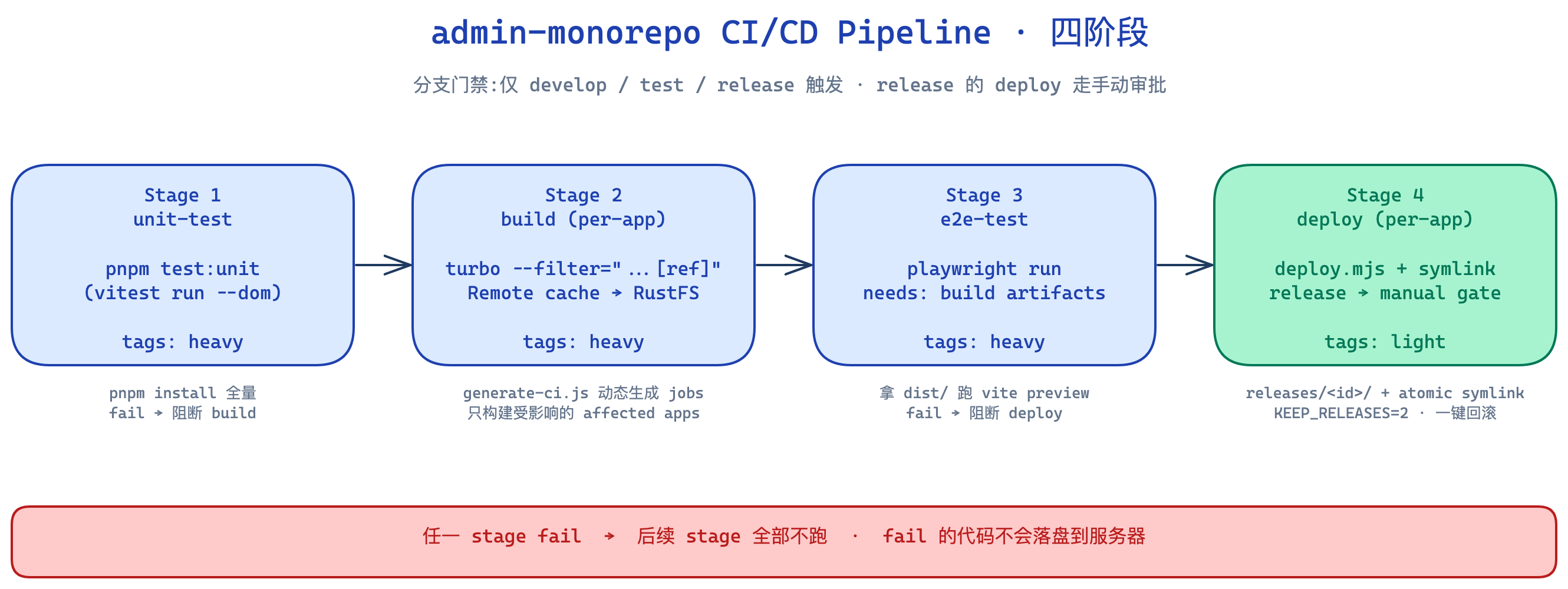
unit-test → build → e2e-test → deploy
每阶段的设计原则:
-
unit-test 在 build 之前 — 不通过的代码不浪费 build 资源
-
build 用 Turbo
--filter="...[ref]"— 只构建受影响 app(...[ref]是上游传播:改@org/ui-layouts时找到所有消费它的 app 并加入构建。我早期写反过一次[ref]...(下游传播),导致”改了 layouts 却零变更”)。generate-ci.js按当前 commit 的变更集动态决定哪些 app 进入 build: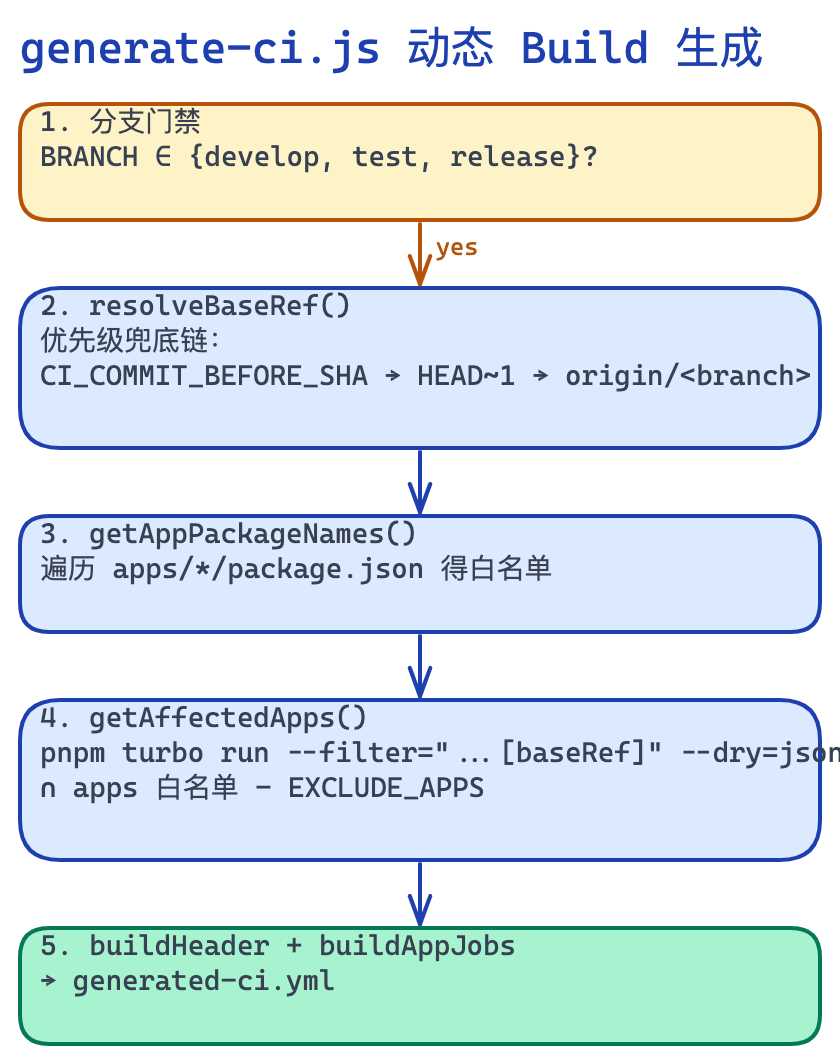
-
e2e-test 在 build 之后 — 用真 build 产物跑真实 vite preview
-
deploy 在 e2e 之后 — 任一 stage fail,后续 stage 全部不跑,fail 的代码不会落盘到服务器
-
分支门禁 — 只让主干分支(develop / test / release)触发,feature 分支跳过
-
审批门禁 — release 分支 deploy 走手动审批
runner 分层:build 用 heavy runner(避免 pnpm install OOM),deploy 用 light runner(不需要重资源)。整套基础设施布局:
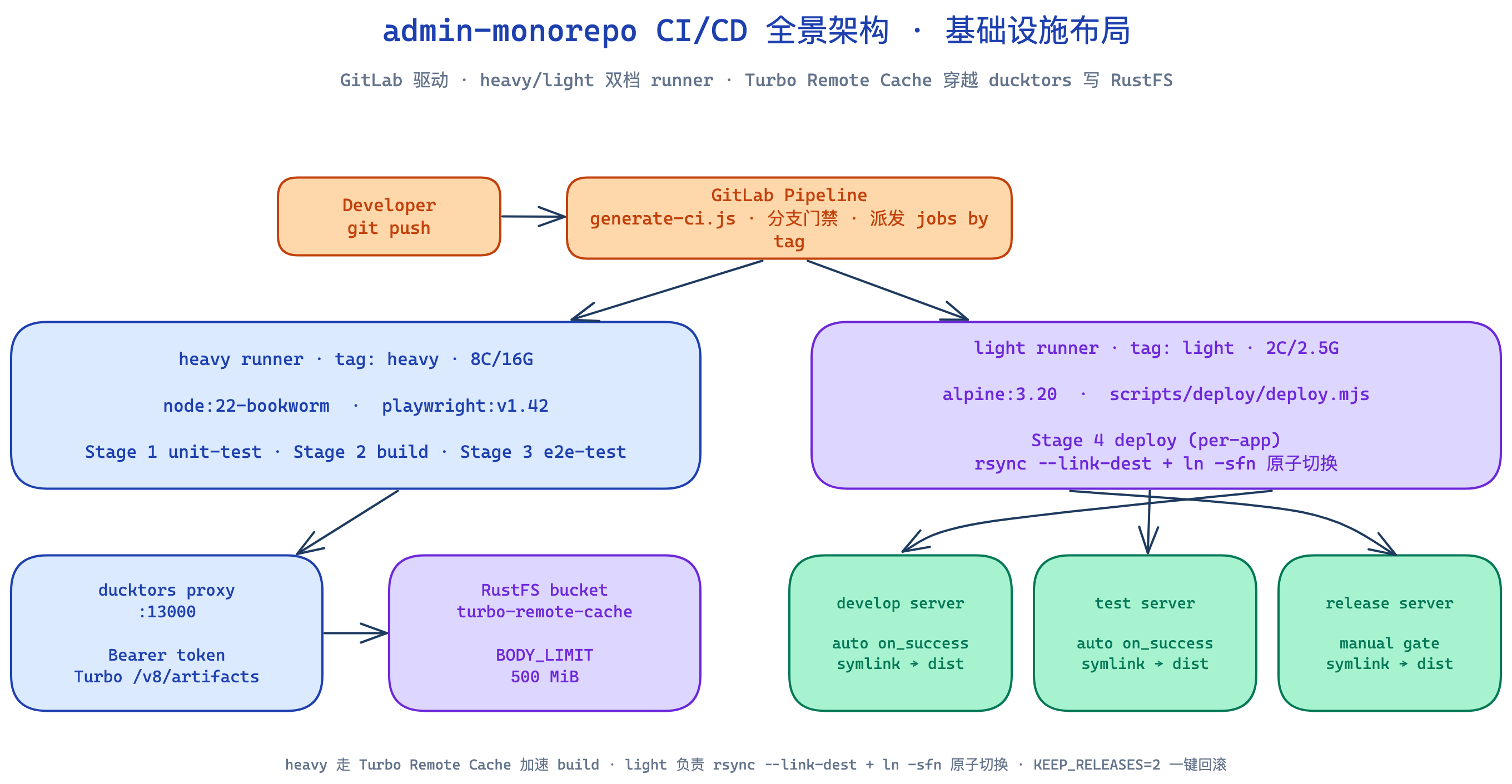
九、产品化操作:FSD 切片即产品边界
9.1 一个完整业务域在 FSD 里长这样
entities/equipment/ ← 领域模型 (model, store, api)
├── model/
│ ├── types.ts
│ ├── store.ts
│ └── schema.ts
└── api/
└── equipment.ts
features/equipment/ ← 交互行为 (按钮、表单、对话框)
├── add/
├── edit/
├── assign/
└── decommission/
widgets/equipment-*/ ← 跨页复用的块
pages/equipment-*/ ← 路由级页面
9.2 抽离六步
- 选定要抽的域,比如
equipment - 跑依赖扫描工具检查切片对其它域的依赖,不干净就先补隔离
- 用脚手架生成新仓骨架
- 把
entities/equipment+features/equipment/*+ 相关widgets/+pages/整体搬进新骨架的src/ - 依赖沿 catalog 一键拉齐;
packages/按处置策略决定跟走还是 UPSTREAM - 跑一遍 CI,独立部署
9.3 母仓 packages/ 的处置策略
| 场景 | 处置策略 |
|---|---|
| 只有母仓在用,且和被拆出去的业务域无关 | 留在母仓 |
| 只有被拆出去的业务域在用(薄封装本来就为它写) | 跟着新产品仓走(整个目录搬迁) |
| 两边都要用,且已经稳定 | 抢在 SPAWN 前提级 UPSTREAM 到基建库,两仓都改消费 @org/*,避免遗留双份 |
| 两边都要用,但还没稳定 | 先在新仓复制一份,打标签记作”技术债”,等稳定再 UPSTREAM;不要在没想清楚之前强行下沉 |
十、关键决策回顾
| 决策 | 选择 | 放弃的方案 | 理由 |
|---|---|---|---|
| 基建层策略 | 独立 monorepo 发布到 Registry | 业务仓内部共享 | 多产品复用、独立发版节奏 |
| 业务层分层 | FSD 六层 | 经典 Vue(api/views/components) | 产品化抽离的物理边界 |
| 老项目迁移节奏 | 渐进式按业务域迁 | 一次性重构 | 业务高速迭代,不能 stop-the-world |
| CI 阶段设计 | unit → build → e2e → deploy | build → deploy | 两端保险,fail 代码不落盘 |
| Turbo filter 方向 | ...[ref](上游传播) | [ref]...(下游传播) | 前者才能让”改 layouts”带上所有 app |
| runner 分层 | heavy + light 按 tag 分流 | 单一 runner | build OOM 风险、deploy 不需要重资源 |
| 部署原子性 | symlink + mv -Tf | 临时目录 + rsync 覆盖 | rename(2) 原子,nginx 零感知 |
| Release 保留策略 | KEEP_RELEASES = 2 | 保留所有 / 保留 1 | 1 个无法回滚,3+ 浪费磁盘 |
| Cache TTL | 14 天 | 7 天 / 30 天 | 命中率衰减曲线的平衡点 |
十一、给打算走类似路的人
如果你也面对一个堆了 N 个业务域的大前端单仓、想往产品化方向重构:
- 先想清楚产品化诉求是不是真的 — 如果只是”代码不整洁”,整理目录就行,不需要这套架构
- 基建库可以延后做 — 早期可以先在应用仓里组织代码,FSD 化先做。等抽离第一个产品时再正式做基建库
- FSD 是必做的 — 这是 SPAWN 的物理刀口,没有它产品化就是空话
- CI/CD 模板要早抽 — 第二个应用级 monorepo 出现时就是必做的时刻,之前可以拖,之后再拖就是双份维护
- 原子部署不是过度工程 — 单服务器、零停机、秒级回滚的需求加起来就值这套机制
- Turbo Remote Cache 必须上 — CI 没 local cache,不上 remote cache 每次都全量构建
整套方案最关键的洞察是**“产品化的物理边界不能事后补”**——目录怎么切、依赖怎么走、构建怎么过、部署怎么走,都得在做架构那一刻就服务于”未来要拆产品”这件事。事后想抠出来,难度等同重写。
主要参考
方法论 & 架构
Monorepo 工具链
CI/CD & 部署
- GitLab CI/CD Pipeline 配置
- GitLab 动态子流水线 (Dynamic Child Pipelines)
- Vitest · Playwright
- rsync
--link-dest· Linuxrename(2)man page
缓存 & 存储
这套架构当前还有 FSD 全量迁移、脚手架代码生成器、CI-kit 抽离这些事没做完。但骨架立起来之后,每一项都是”待拆解的工程任务”,而不是”待解决的架构问题”。这是这次重构最值钱的产出。