我准备开始啃 Spring AI,但 Spring AI 是坐在 Spring Boot + Spring MVC + Servlet + Tomcat 之上。如果不理清”一个请求是怎么从浏览器走到我的代码再走回去的”,每写一个新功能我都会卡在”这玩意从哪冒出来的、应该插在哪一层”。
这篇是我一次性把这条链路搞透的笔记。读完之后,看任何 Spring 后端代码都能回答三个问题:
- 它跑在哪一步?(Filter? Interceptor? Controller? Advisor?)
- 它需要哪一步的什么数据?
- 它发生在启动期还是运行期?
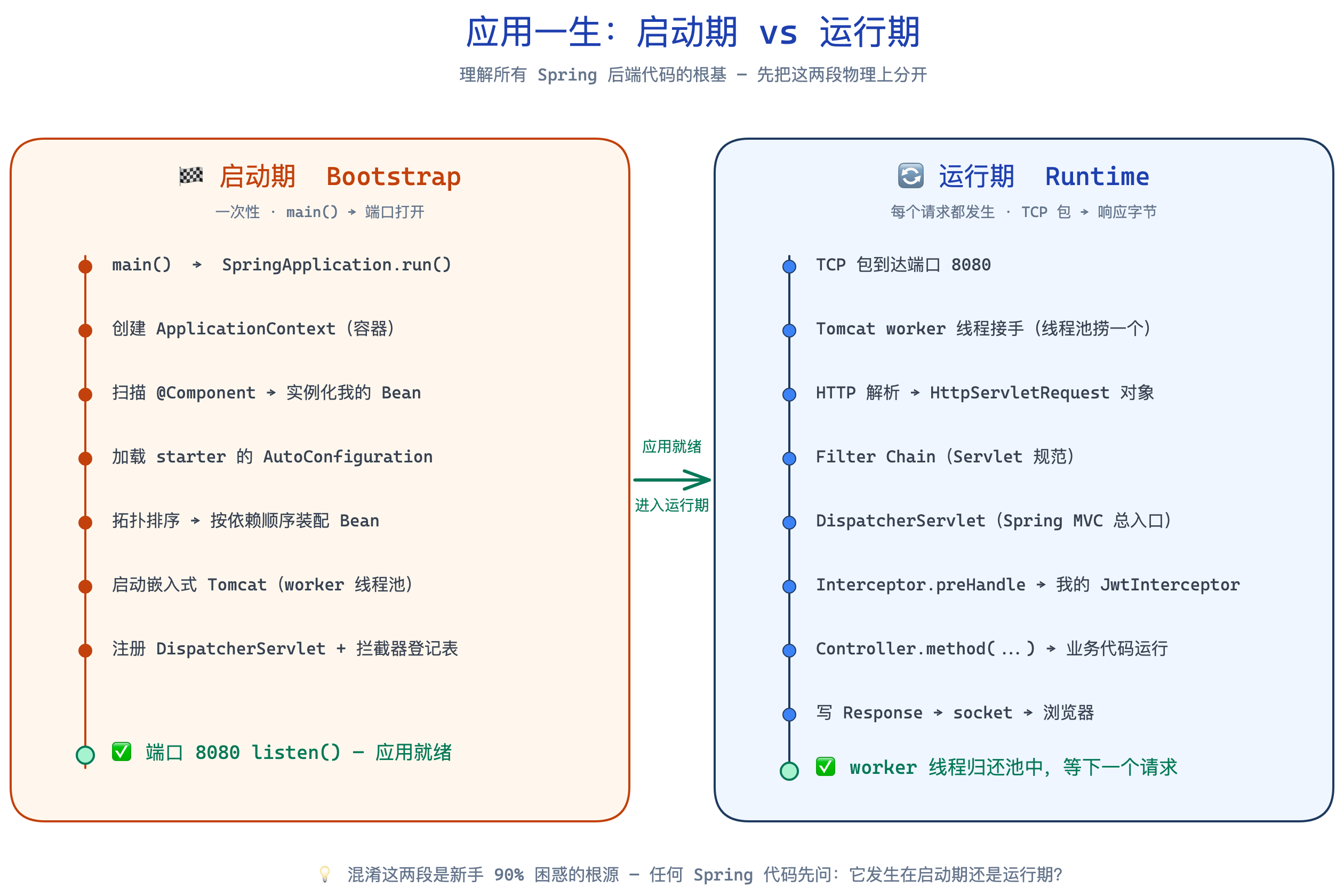
一、启动期 vs 运行期 ⭐
任何 Spring Boot 应用都有两个完全不同的时期。这是理解一切的根。
| 时期 | 触发 | 频率 | 主要做什么 |
|---|---|---|---|
| 启动期 | main() 开跑 | 一次性 | 装配 Bean、读 yml、启动 Tomcat、注册 DispatcherServlet |
| 运行期 | TCP 包到达 | 每个请求一次 | 解析 HTTP、跑拦截器、调 Controller、写响应 |
我之前 90% 的”这玩意从哪冒出来的”困惑,都是没分清这两段。看 Spring 代码先问自己:它发生在哪一段?
二、技术栈分层
Spring Boot 应用是一个 8 层蛋糕。业务代码坐在最顶层,每往下一层都是别人帮我做好的事。

| 层 | 是什么 |
|---|---|
| 业务代码 | @Controller / @Service / @Repository |
| Spring AI | starter + auto-config + ChatClient 等抽象 |
| Spring Data / Security / Web | 各 starter 各自的抽象 |
| Spring Boot | auto-config + 嵌入式 Tomcat + starter 体系 |
| Spring Framework | IoC 容器 / DI / AOP(核心,跟 HTTP 无关) |
| Spring MVC | DispatcherServlet + HandlerMapping + ArgumentResolver |
| Servlet API | Java 处理 HTTP 的标准接口(1997 年定的) |
| Tomcat | Servlet 容器(HTTP 服务器) |
关键关系:
- Tomcat 不知道 Spring——它只认 Servlet 规范的接口
- DispatcherServlet 是 Servlet 与 Spring 的衔接点——本身实现了 Servlet 接口,内部跑 Spring MVC 的调度逻辑
- Spring Framework 跟 HTTP 没关系——原始 Spring 是个对象管理器,可以用它写命令行程序
- Spring Boot 不是新框架——是 Spring + 嵌入式 Tomcat + auto-config 打包好的”启动器”
- Spring AI 的套路完全一致——starter + auto-config + 一组抽象,跟 Spring Data / Spring Security 一个模式
三、启动期 9 步
main() 跑起来到端口 listen,完整 9 步。之后整个流程不再发生第二次。

SpringApplication.run()创建 Spring 上下文- 读取
application.yml/application.properties @ComponentScan扫描我写的@Component/@Service/@Controller@EnableAutoConfiguration加载所有 starter 的 auto-config- 实例化 Bean(按依赖关系排序)
- 注入依赖(构造函数 / setter / 字段)
- 启动嵌入式 Tomcat
- 注册 DispatcherServlet 到 Tomcat
- 监听端口(
Started on port 8080)
@SpringBootApplication 拆开就是三个注解:
| 子注解 | 触发哪一步 | 干什么 |
|---|---|---|
@Configuration | — | 标记这个类本身是 Bean 配置 |
@ComponentScan | 步骤 3 | 扫描我写的 @Component |
@EnableAutoConfiguration | 步骤 4 | 加载所有 starter 的 auto-config |
每加一个 starter / 改一个 yml 配置 / 写一个 @Component 时,问自己:
- 它会在第几步被加载?
- 它依赖谁?该谁先于它装配?
- 它会进 ApplicationContext 这个 Map 吗?
能答上这三个问题 = 真的懂启动期。
四、运行期:一次请求的 15 步 ⭐⭐⭐
这是核心。把这张图刻进脑子,写任何功能都知道往哪儿插。

| # | 在哪 | 做什么 |
|---|---|---|
| 1 | OS 内核 | 字节进 socket 缓冲(TCP) |
| 2 | Tomcat | Acceptor → Poller → Worker 接手(线程池捞一根) |
| 3 | Tomcat | bytes → HttpServletRequest(Servlet API) |
| 4 | Filter Chain | 编码 / CORS / 压缩 / Spring Security |
| 5 | DispatcherServlet | service(req, resp) — Spring 入口 |
| 6 | HandlerMapping | URL → Controller 方法 |
| 7 | Interceptor | preHandle(我的 JwtInterceptor 在这) |
| 8 | HandlerAdapter | ArgumentResolver 解析 @RequestParam 等 |
| 9 | 业务代码 | ★ 反射调 Controller 方法 |
| 10 | ReturnValueHandler | 返回值转换(Flux<String> → SSE 等) |
| 11 | HttpMessageConverter | 对象 → JSON(Jackson) |
| 12 | Interceptor | postHandle(改 header / body) |
| 13 | DispatcherServlet | 写 OutputStream(响应字节进 socket buffer) |
| 14 | Interceptor | afterCompletion(清 ThreadLocal、记日志) |
| 15 | Tomcat | 写回 socket → 浏览器,worker 归还池 |
三个反直觉事实:
- 第 9 步才是我的代码运行——前 8 步全是框架在准备
- 整段路径只用一根 worker 线程——所以 request / userId / traceId 绑在它身上是安全的
- 拦截器有三个钩子:
preHandle(步骤 7) /postHandle(步骤 12) /afterCompletion(步骤 14),各自能看到的 response 状态不同
五、线程模型(容易踩坑)
三个事实:
- 每个 HTTP 请求 = 一个 worker 线程(Tomcat 线程池里捞一个)
- 线程数有限(默认 200)→ 请求数 > 线程数则排队
- Bean 是单例,线程是多个 → 单例 Bean 被多线程并发访问
三个推论:
推论 1:Bean 字段不能放可变状态
@Component
class BadService {
private int counter = 0; // ❌ 多线程加它就乱套
public void hit() { counter++; }
}正确做法:用 AtomicInteger / ConcurrentHashMap,或把状态放进请求级容器(HttpServletRequest.attributes)/ 线程级容器(ThreadLocal)。
推论 2:HttpServletRequest 天然线程安全
每个线程一个独立 request 对象。setAttribute 怎么写都不会串。
推论 3:ThreadLocal 是”穿透方法签名传数据”的神器,但用完必须清
ThreadLocal<String> CURRENT_USER = new ThreadLocal<>();
// preHandle 里:
CURRENT_USER.set(userId);
// 业务代码任何深度都能取:
CURRENT_USER.get();
// afterCompletion 里:
CURRENT_USER.remove(); // ⚠️ 不清就内存泄漏(线程被池复用)Spring Security 的
SecurityContextHolder就是 ThreadLocal 实现的。
六、5 个扩展点:写功能时该插哪?
写新功能第一个该问的问题是:这事我应该插在哪一层?
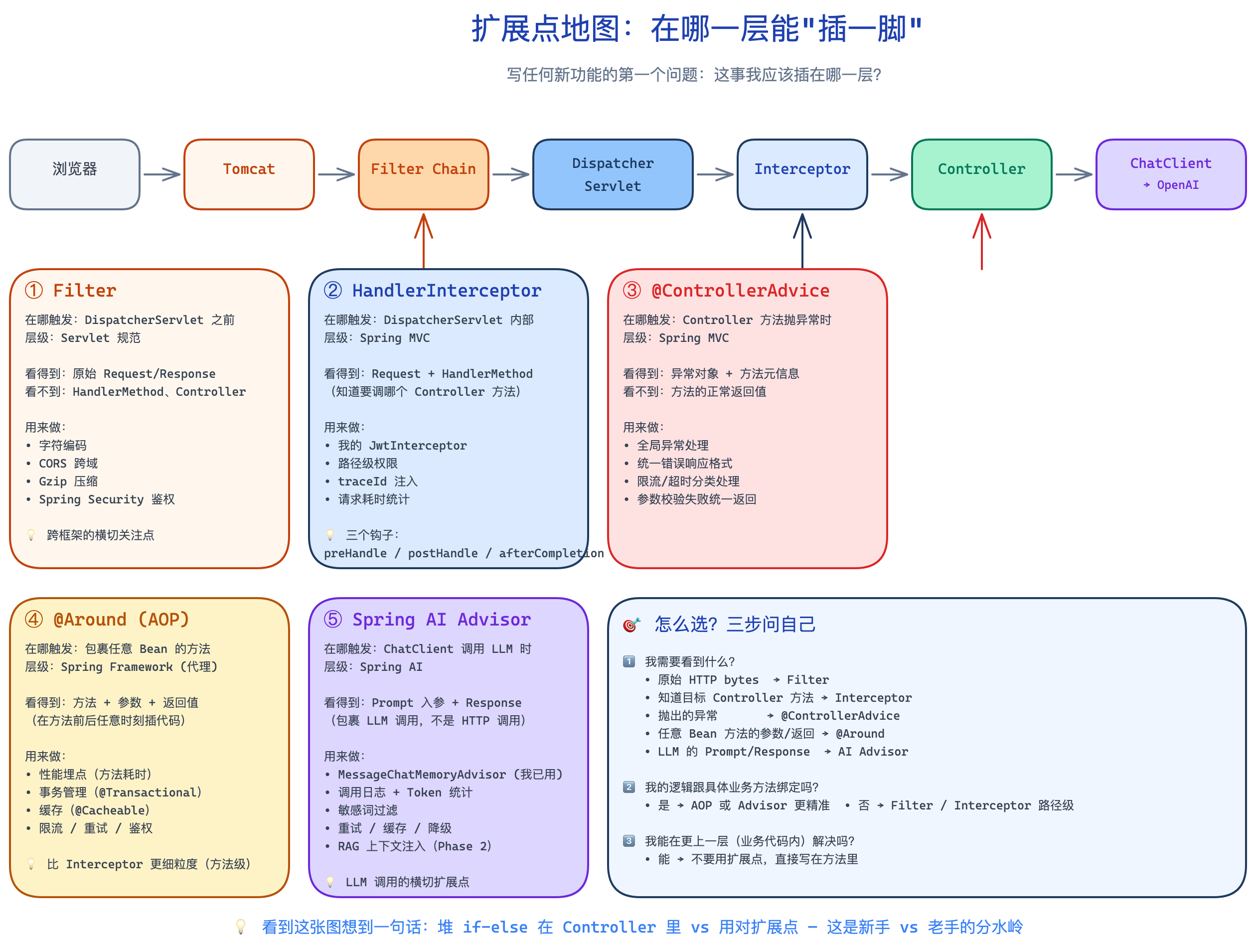
| 扩展点 | 在哪触发 | 看得到 | 典型用途 |
|---|---|---|---|
| Filter | DispatcherServlet 之前 | 原始 Request/Response | 编码、CORS、压缩、Spring Security |
| HandlerInterceptor | DispatcherServlet 内部 | Request + 已匹配的 HandlerMethod | JwtInterceptor、traceId、耗时统计 |
| @ControllerAdvice | Controller 抛异常时 | 异常对象 + 方法元信息 | 全局异常、统一返回格式 |
| @Around (AOP) | 任意 Bean 方法前后 | 方法 + 参数 + 返回值 | 性能埋点、事务、缓存、限流 |
| Spring AI Advisor | ChatClient 调 LLM 时 | Prompt + Response | 记忆、Token 统计、敏感词、RAG |
怎么选——每次问自己三步:
-
我需要看到什么?
- 原始 HTTP bytes → Filter
- 知道目标 Controller 方法 → Interceptor
- 抛出的异常 → @ControllerAdvice
- 任意 Bean 方法的参数/返回 → @Around
- LLM 的 Prompt/Response → AI Advisor
-
我的逻辑跟具体业务方法绑定吗?
- 是 → AOP / Advisor 更精准
- 否 → Filter / Interceptor 路径级
-
我能在更上一层(业务代码内)解决吗?
- 能 → 不要用扩展点,直接写在方法里
七、整合题(自检)
需求:给所有
/api/chat/**请求加一个统计——记录每次请求耗时(ms),最后写日志。
回答:
- 应该插在哪个扩展点?
- 在哪一步开始计时,哪一步结束?
- 为什么不用别的扩展点?
参考答案:
- HandlerInterceptor。理由:路径级匹配 + 能拿到 HandlerMethod + 跨整个 Controller 调用周期
preHandle开始计时(存到 request attribute 或 ThreadLocal),afterCompletion结束并写日志。注意是 afterCompletion 而不是 postHandle——postHandle 只是方法返回,response 还没真正写完;afterCompletion 是响应已发完的最后时机,统计耗时最准- 不用 Filter:会算上其他 Filter 的耗时,且看不到 HandlerMethod,无法记录”是哪个接口慢了”。不用 @Around:要么作用太广(所有 Service 方法),要么作用太窄(只 Controller 方法),无法精确对应一次”请求”。不用 @ControllerAdvice:它只在异常时触发
八、内化方法
不是背——是每写一个新功能就回头对照 三件事:
- 它跑在哪一步?(Filter? Interceptor? Controller? Advisor?)
- 它需要哪一步的什么数据?(原始 bytes? servlet request? 方法参数? 返回对象?)
- 它在启动期还是运行期生效?
答清楚这三个问题 = 写出来的代码不会插错地方。这是从新手走向老手的分水岭。
这套底层模型适用于所有 Spring Boot 应用,包括 Spring AI。下次看 Spring AI 的 Advisor 或 ChatClient 实现,回到这条链路对照,每段代码该在第几步生效就清楚了。